Indexing Pipeline Deep Dive¶
Prism turns a Git repository into a hybrid lexical-semantic-structural index that AI agents query through a small set of MCP tools. This guide explains how a git push becomes a row in prism.code_chunks, how that row gets retrieved by search_code, and what each performance budget means for the user. It is the reference for "why did Prism return that?" — and for anyone tuning ingestion or operating a self-hosted gateway.
When to read this¶
- A search returned the wrong file and you want to know which retrieval leg is at fault.
- You see
indexed_atlagging by hours and want to know who refreshes the index, and when. - You connected a repo via the Console but the dashboard shows "indexing" for longer than expected — you need a mental model of the steps.
- You're writing tools or operators against the gateway and need the actual schema.
- You're debugging a stale module map after a large rename, or a missing description on a fresh chunk.
If you only need the user-facing surface (overlays, CLI commands), read Branches & Overlays and CLI Workflow first; this guide is the layer underneath.
Three tiers of indexing¶
Three independent paths can write into the index. They differ by who triggers and what scope — the chunking + embedding pipeline they hand off to is identical.
| Tier | Trigger | Scope | Code | Use case |
|---|---|---|---|---|
| Tier 1 | Local file save / prism sync |
Single file | prism.sync.tier1.Tier1SyncClient → POST /api/v1/ingest/file |
Editor-driven freshness for the developer's own machine |
| Tier 2 | Local git commit |
Files in the commit | prism hooks install writes .git/hooks/post-commit, which invokes prism sync → Tier 1 endpoint per file |
Bridge between save and push — your teammates see your work after commit, before push |
| Tier 3 | GitHub push webhook | All changed files in the push | _handle_github_webhook (apps/prism/prism/gateway/console_routes.py) → ingestion queue → IngestionWorker.process_job via POST /api/v1/ingest/webhook |
Primary path for shared freshness across a team |
Tier 1 and Tier 2 both call the same /api/v1/ingest/file endpoint (and its diff-mode sibling /api/v1/ingest/diff). Tier 3 calls /api/v1/ingest/webhook, validates the GitHub HMAC, parses the push into a PushEventData, then runs the same chunk → embed → store pipeline plus a repo-map rebuild when the push has structural changes.
For day-to-day work as a coding-agent user, Tier 3 is what keeps the team's index fresh; Tier 1 / Tier 2 are nice-to-haves for solo development. The CLI's auto-overlay over working-tree dirty files closes the freshness gap for the developer's own unpushed edits regardless of tier.
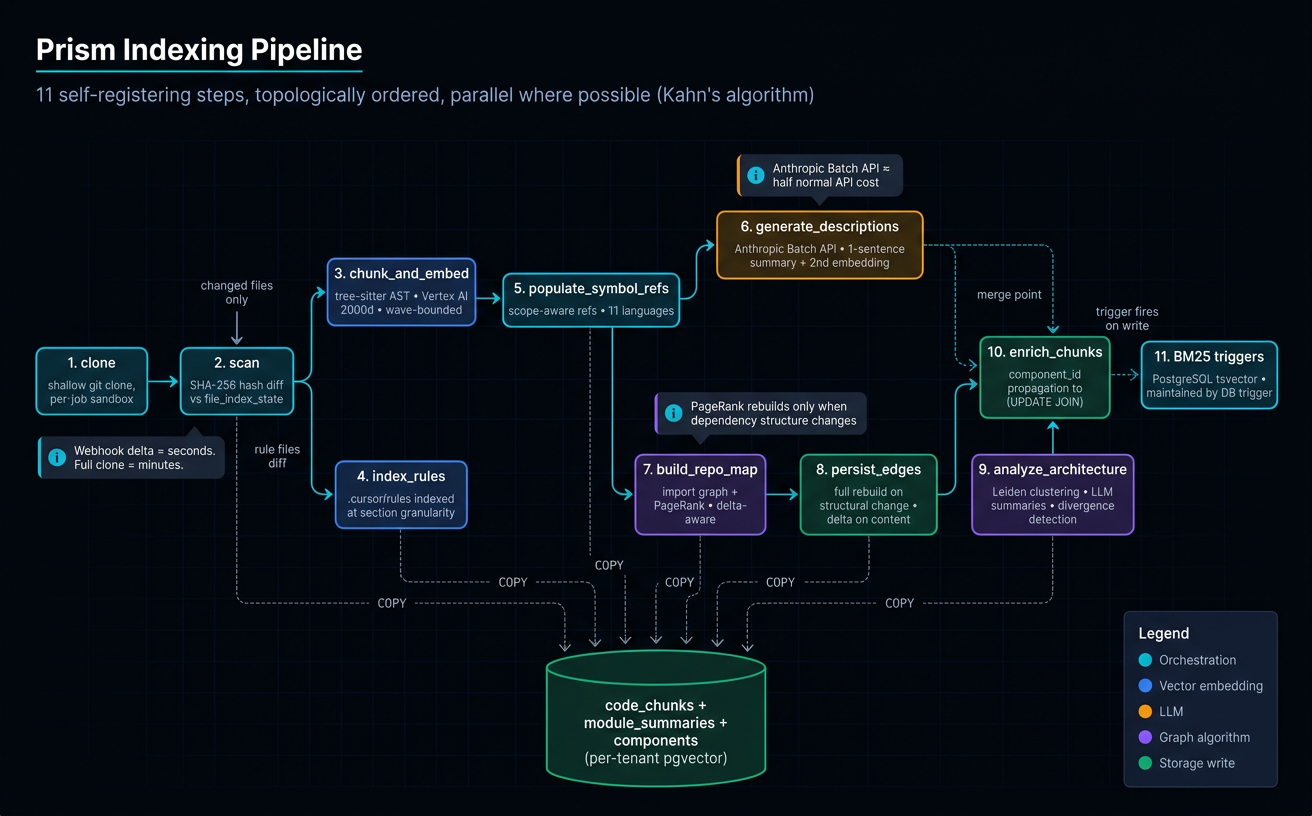
Pipeline steps¶
The same step DAG runs for every ingestion path, scoped to the file set the trigger provided. Steps are self-registering — each declares its dependencies and the orchestrator (PipelineController) runs them via Kahn's topological sort. Independent branches run concurrently.
flowchart TD
A[Trigger: file save / commit / push] --> B[1. clone]
B --> C[2. scan]
B --> D[3. index_rules]
C --> E[4. chunk_and_embed]
E --> F[5. populate_symbol_refs]
E --> G[6. generate_descriptions]
E --> H[7. build_repo_map]
H --> I[8. persist_edges]
I --> J[9. analyze_architecture]
J --> K[10. enrich_chunks]
E -.trigger.-> L[(11. BM25 tsvector trigger — automatic)]
F --> M[code_chunks + symbol_references + module_summaries written]
G --> M
K --> MStep source lives in apps/prism/prism/pipeline/steps/; each module exports a StepDefinition with name, dependencies, and a run() coroutine. Adding a step is a matter of dropping a file in that directory — registration is automatic.
1. clone¶
Shallow git clone --depth 1 of the target ref into a temp working directory (Tier 3 webhook, Console reindex). For Tier 1 / Tier 2 endpoints the file content arrives in the request body and the orchestrator skips the clone — scan runs against the supplied diff instead.
2. scan¶
The diff step. Walks the working tree (or the supplied file list) and computes the set of files to chunk, the set of files to delete, and the set of unchanged files. For Tier 3 incremental ingest, scan reads PushEventData.added/modified/removed. For full reindex, it enumerates everything. This is where Prism becomes a delta processor: downstream steps only touch what changed.
3. index_rules¶
Runs in parallel with scan. Indexes coding-convention files (CLAUDE.md, .cursor/rules/, AGENTS.md, CONTRIBUTING.md) into a dedicated table read by the get_codebase_conventions MCP tool. Decoupled from the chunk pipeline because rules are tiny and need fast updates independent of chunk re-embedding.
4. chunk_and_embed¶
Two operations fused into one step because they share a batch boundary. prism.chunking.ast_chunker.AstChunker parses each scanned file. For Python, TypeScript, TSX, and JavaScript its _chunk_with_ast() method calls into prism.chunking.semantic_chunker.chunk_semantic(), which applies an opinionated allowlist: emit one chunk per class / function / method / interface / type alias / enum / module-level constant; suppress JSX elements, lambdas, callbacks, and imports as children of their parent definition. Adjacent small siblings (consecutive ≤5-line types) are merged.
For all other languages, AstChunker falls back to the upstream treesitter-chunker. If tree-sitter parsing fails entirely, it falls back to line-based splitting. No file ever produces zero chunks for non-empty content.
Each chunk carries:
chunk_text— the literal source slicestart_line/end_linelanguagecontent_hash— SHA-256 of the chunk text, used for dedup and cache lookupsymbol_name,symbol_kind,signature,docstring— extracted from the AST when availablequalified_name—Class.methodform for nested definitions (populated only for class children)
Immediately after chunking, each chunk's text is sent to Vertex AI (gemini-embedding-001, 2000 dimensions) via the Embedder protocol (prism.ingestion.handlers.Embedder). Embedding is batched (250 texts per API call) with a concurrency semaphore (5 parallel requests) to stay under provider quotas. The vector lands in code_chunks.embedding (a vector(2000) column with an HNSW index per partition).
Production note: the semantic chunker reduced average chunk counts by ~60% on a mixed Python/TSX repo vs. the upstream chunker, primarily by collapsing JSX-heavy components and lambda-heavy dataclasses into single chunks.
5. populate_symbol_refs¶
Runs in parallel with generate_descriptions and build_repo_map. Uses tree-sitter scope queries (11 languages) to extract every symbol reference — Foo.bar() call sites, identifier reads, type references — into the symbol_references table. This is what powers the find_references MCP tool: the table is pre-built at ingest time, so a refs query is a single indexed lookup rather than a runtime AST traversal.
6. generate_descriptions¶
For non-boilerplate source files, this step calls an LLM (Anthropic Claude Haiku in production, often via Batch API for cost; Vertex gemini-2.5-flash-lite as fallback) to produce a one-sentence natural-language description of each chunk. The description is then embedded by the same Embedder and stored in description_embedding. A per-run rate-limit budget plus a content-hash cache (_restore_descriptions_from_cache) means re-runs are cheap and rate-limit failures degrade gracefully rather than blocking the pipeline.
Descriptions serve two purposes:
- They are the fourth retrieval leg — natural-language queries match descriptions even when the code uses very different vocabulary.
- They are returned alongside code chunks in tool responses, so agents can decide whether to read the chunk body without paying for the bytes.
If the LLM is unavailable or over budget, the chunk is still indexed (text + code embedding + BM25 + symbol_refs). Description coverage is tracked and a backfill endpoint repairs gaps — see Description backfill.
7. build_repo_map¶
prism.repomap.builder.ImportGraphBuilder parses imports from every source file (Python, TypeScript, TSX, JavaScript, Swift) into a directed module graph. prism.repomap.builder.PageRankScorer then computes the PageRank score for every node.
Three design choices worth knowing:
- Global graph scoring. All modules across all top-level directories share one graph — a frontend file importing a backend type contributes to a unified ranking, not a per-directory island.
- Dangling-leak parameter. Nodes with no outbound imports redistribute only ~15% of their score uniformly (configurable as
dangling_leak), preventing isolated scripts from artificially out-ranking core services. - Python relative imports resolved.
from .models import Xandfrom ..core import Yare resolved by counting leading dots and ascending directories — most off-the-shelf graph builders miss these edges. TypeScript path aliases (@/...) are resolved by suffix matching.
Each module gets a row in prism.module_summaries with summary, symbols (JSONB), and page_rank. The prism module-map CLI tool reads from this table and assigns each entry a tier (core / significant / peripheral) based on its score's position in the distribution.
In Tier 3, the repo map is rebuilt only when the push had structural changes (PushEventData.has_structural_change) — pure content edits skip the rebuild for speed. Full reindex via PipelineController always rebuilds.
8. persist_edges¶
Materializes the import-graph edges built in step 7 into the module_edges table — (source_module, target_module, edge_kind). Decoupled from build_repo_map so PageRank can run in memory and only the persistent edge set hits the database, and so downstream architecture analysis has a stable, query-able graph to walk.
9. analyze_architecture¶
Runs the Leiden clustering algorithm over the persisted module graph to find architectural components (groups of tightly-coupled modules). Each module gets component_id + component_role (entry_point / hub / leaf / peripheral) written back into module_summaries. This is what the get_architecture MCP tool returns, and what powers the architecture-aware fields in get_module_map.
10. enrich_chunks¶
Backfills the component_id / is_hub / is_entry_point fields from module_summaries onto each chunk row. After this step every code_chunks row knows which component it belongs to, so search_code can boost or filter by component without joining module_summaries at query time.
11. BM25 tsvector triggers (automatic)¶
content_tsv and description_tsv are PostgreSQL tsvector columns populated by a database trigger (see TSVECTOR_FUNCTIONS in prism/storage/ddl.py) on every chunk row insert or update. No application code touches tsvector directly — writing the chunk row is enough to make it BM25-searchable. It's listed as a pipeline step because it's a load-bearing part of retrieval, but it has no Python step file: the trigger does the work atomically with the chunk insert.
4-way RRF retrieval¶
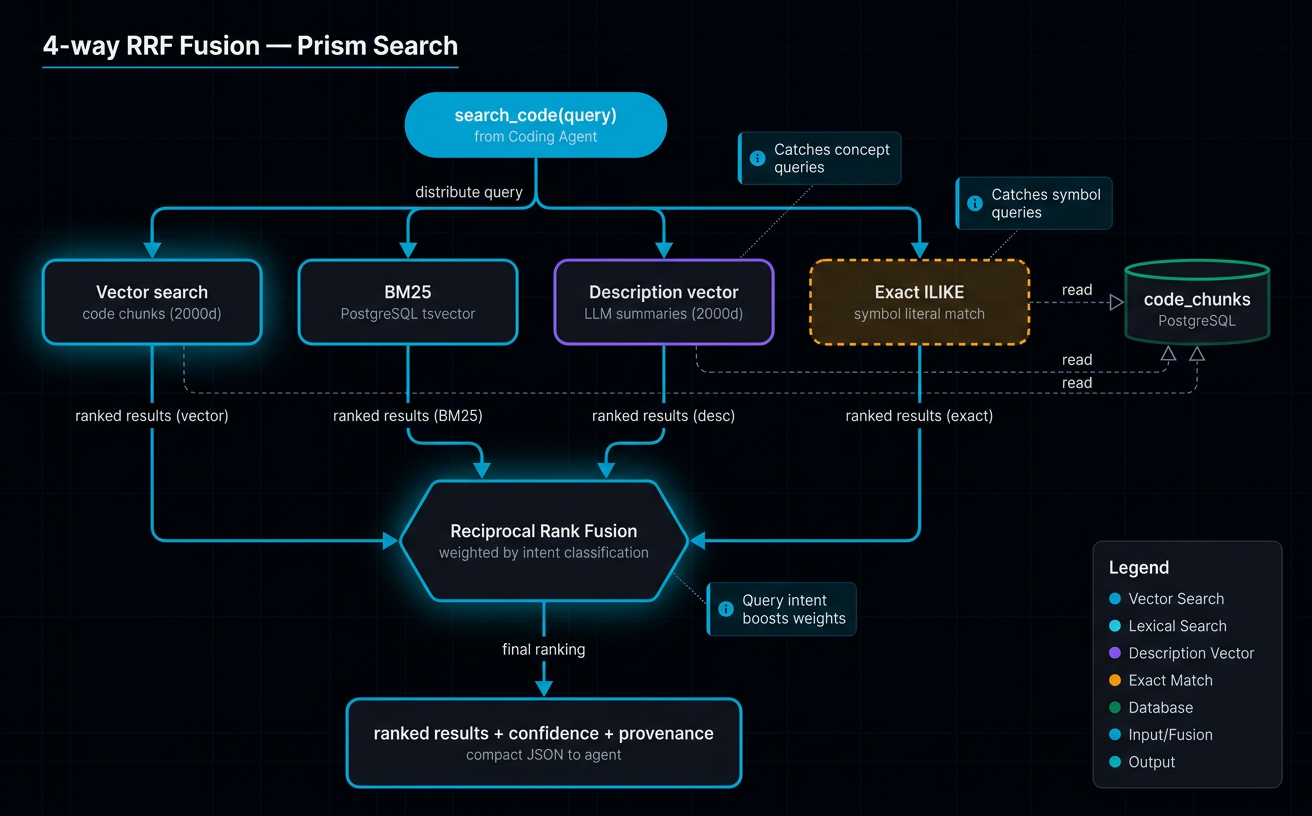
This is the query-side counterpart to the pipeline. When an agent calls search_code("JWT validation middleware"):
Query
├─→ Vector similarity on `embedding` → top N candidates
├─→ BM25 over `content_tsv` + `description_tsv` → top N candidates
├─→ Vector similarity on `description_embedding`→ top N candidates
└─→ Exact ILIKE on `chunk_text` / `symbol_name` → top N candidates
│
▼
Reciprocal Rank Fusion (k = 60):
score(chunk) = Σ 1 / (60 + rank_in_leg) across legs the chunk appears in
│
▼
Optional semantic reranker (Google `semantic-ranker-fast-004`)
│
▼
Response: results[] + confidence + provenance + next_actions
confidence reports how many legs agreed (high = 2+ legs, including any exact hit). provenance lists per-leg hit counts so a caller can see why a result ranked where it did. Each leg has a different failure mode — vector misses literals, BM25 misses synonyms, descriptions miss code-level detail, exact misses everything not verbatim — and RRF takes the consensus.
Schema map¶
The three tables you'll inspect most when reasoning about index state. Authoritative DDL is in apps/prism/prism/storage/ddl.py; this is the version current as of 2026-05-20.
prism.code_chunks¶
The unit of storage and the target of every read tool. List-partitioned by tenant_id.
| Column | Type | Notes |
|---|---|---|
chunk_id |
BIGSERIAL |
Part of composite PK with tenant_id |
tenant_id |
UUID |
Partition key |
repo_id |
UUID |
Resolved from repos.full_name at ingest |
file_path |
TEXT |
Repo-relative |
start_line / end_line |
INT |
1-indexed |
chunk_text |
TEXT |
Raw source slice |
language |
VARCHAR(50) |
python, typescript, markdown, unknown, … |
embedding |
vector(2000) |
Code-text embedding (HNSW indexed per partition) |
content_tsv |
TSVECTOR |
BM25 over code text (trigger-populated) |
content_hash |
VARCHAR(64) |
SHA-256, used for dedup + description cache |
indexed_at |
TIMESTAMPTZ |
Surfaced to clients as indexed_at + index_age_seconds |
symbol_name, symbol_kind, signature, docstring |
TEXT |
AST metadata |
description |
TEXT |
LLM-generated, nullable |
description_tsv |
TSVECTOR |
BM25 over description |
description_embedding |
vector(2000) |
Fourth-leg retrieval vector |
branch |
TEXT |
'' for default-branch chunks; populated for branch-overlay chunks |
qualified_name |
TEXT |
Class.method for class children; NULL otherwise (partial index) |
prism.module_summaries¶
One row per source file, materialized for get_module_map and PageRank-based search boosts.
| Column | Type | Notes |
|---|---|---|
tenant_id, repo_id |
UUID |
Tenant-partitioned reads |
module_path |
TEXT |
Repo-relative |
summary |
TEXT |
Concatenated signatures + docstrings |
symbols |
JSONB |
Array of symbol metadata for fast outline |
page_rank |
FLOAT |
0..1, drives tier and relative_score |
branch |
TEXT |
'' for default; per-branch summaries for overlays |
is_entry_point, is_hub, component_id, component_role |
— | Architecture-intelligence enrichment |
Unique on (tenant_id, repo_id, module_path, branch) — overlay summaries coexist with default-branch summaries.
prism.branch_overlays¶
The registration table for long-lived feature branches. See Branches & Overlays for the read-path behaviour.
| Column | Type | Notes |
|---|---|---|
tenant_id, repo_id |
UUID |
Composite scope |
branch |
TEXT |
Branch name; part of PK |
base_branch |
TEXT |
Default 'main'; the overlay diff is computed against origin/<base_branch> |
created_at, last_pushed_at |
TIMESTAMPTZ |
Used by stale-overlay refresh hints (>24h triggers a next_actions entry) |
status |
TEXT |
'active' while in use; tombstoned on prism branch delete |
deleted_files |
TEXT[] |
Files removed on the overlay branch — read tools subtract these |
Known gap (as of 2026-05-20): no head_sha column. The diff baseline is origin/<base_branch>, so a force-push to the overlay head can drift the diff set. Tracked for a follow-up if a force-push incident occurs.
Tier 1 — file watcher / prism sync¶
Tier1SyncClient (apps/prism/prism/sync/tier1.py) is the async HTTP client. The user-facing entry point is prism sync --changed "path1 path2 …" --repo Owner/Name, which the post-commit hook also calls.
Constants worth knowing:
DEBOUNCE_SECONDS = 1.0— repeated saves of the same file within 1s skip the network.MAX_RETRIES = 3,BACKOFF_BASE = 1.0— exponential backoff per file.fire_and_forget(...)— used by watchers that don't want to await each sync.
Each sync_file call POSTs to /api/v1/ingest/file with {repo, file_path, content, branch?, commit_sha?}. The server runs the chunk → embed → store pipeline for just that file, atomically replacing prior chunks for (tenant, repo, file_path).
Tier 1's freshness is bounded by: your editor saving + the debounce + one HTTP round trip + the gateway pipeline (typically <2s for a single file). Teammates do not see Tier 1 edits — they're local to the writer's machine.
Tier 2 — post-commit hook¶
prism hooks install writes .git/hooks/post-commit with:
#!/bin/sh
# Prism post-commit hook — syncs changed files to the hosted index.
CHANGED=$(git diff-tree --no-commit-id -r --name-only HEAD)
# … invokes `prism sync` in the background with the changed list
The hook is idempotent (re-running install doesn't duplicate content) and runs in the background so it doesn't slow git commit. Uninstall with prism hooks uninstall.
Tier 2 bridges the gap between Tier 1 (per-save, single machine) and Tier 3 (per-push, shared). It's useful when you commit often locally and want your most recent commit reflected in the shared index immediately, without waiting for the next git push.
Tier 3 — GitHub webhook¶
Tier 3 is the production path. When you connect a repo via the Console, it installs a GitHub push webhook pointing at /api/v1/ingest/webhook on the gateway. Each push fires:
- HMAC validation (
validate_github_signature) — rejects unsigned or tampered payloads with401. - Push event parsing (
parse_push_event) — extractsrepo,branch,commit_sha, andadded/removed/modifiedfile lists. Branch-filter logic skips pushes to non-indexed branches. - Incremental ingest —
_handle_github_webhook(apps/prism/prism/gateway/console_routes.py) enqueues a job on the ingestion queue; theIngestionWorker.process_jobloop picks it up and runshandle_ingest_difffor the changed files: deletes stale chunks for modified/removed files, then queues re-indexing. - Repo-map rebuild — only when
PushEventData.has_structural_changeis true (file added or removed). Pure content edits skip this for speed. - Optional architecture analysis —
AnalyzeArchitectureStepruns post-index if enabled.
Webhook delivery is observable in Cloud Logging via jsonPayload.tool="webhook" plus the structured fields repo, branch, commit_sha. Failures (HMAC mismatch, malformed payload, unknown repo) are logged at WARNING/ERROR with the same shape.
Re-index triggers¶
| Trigger | Endpoint / mechanism | Scope | Touches module_summaries? |
|---|---|---|---|
| GitHub push webhook | POST /api/v1/ingest/webhook (Tier 3) |
Files in the push | Only on structural change |
prism sync from CLI / Tier 2 hook |
POST /api/v1/ingest/file (Tier 1) |
One file per call | No |
prism sync --changed batch |
Same, looped | List of files | No |
| Console "Re-index" button | POST /api/v1/console/repos/{id}/index |
Whole repo (full reindex via PipelineController) |
Yes — full rebuild |
| Backfill descriptions | POST /api/v1/repos/{repo_id}/backfill-descriptions |
Chunks missing descriptions | No |
prism branch create <branch> |
Register overlay → backfill chunks for branch-only files | Branch-scoped chunks | Yes for branch-scoped summaries |
A full reindex wipes and re-derives every chunk + PageRank score. It's the right tool after a large refactor, a tree-sitter grammar upgrade, or a chunker version bump (CHUNKER_VERSION). For routine pushes, Tier 3 incremental ingest is sufficient.
Description backfill¶
LLM descriptions are best-effort. Coverage gaps appear when:
- Vertex / Anthropic rate limits exhaust the per-run budget.
- Description providers were disabled during a window.
- Older chunks predate the description-embedding feature.
The endpoint POST /api/v1/repos/{repo_id}/backfill-descriptions walks code_chunks WHERE description IS NULL for the repo and runs the description + embedding step. It's an idempotent, cache-friendly job — re-running it picks up only the still-empty chunks. In production, it runs on Cloud Run so it inherits the Vertex AI service-account credentials; running it locally requires those credentials in your environment.
If the dashboard shows "indexing complete" but searches return chunks with "description": null, a backfill is the cure.
Performance budgets¶
Budgets are observed in production with the default chunker + Gemini embedding + Anthropic descriptions, on a hosted Cloud Run gateway.
| Operation | Budget |
|---|---|
| Full reindex (~500 source files) | 2–3 minutes |
| Incremental ingest (~10 changed files via Tier 3) | ~15 seconds |
| Single-file Tier 1 ingest | <2 seconds (P95) |
search_code end-to-end |
P95 < 500 ms |
get_module_map |
P95 < 200 ms |
get_symbol_definition |
P95 < 100 ms |
| MCP query latency overall (gateway) | P95 < 500 ms |
What these mean for the user:
- After a
git push, expect your teammates to see the new code insearch_codewithin ~30 seconds for normal-sized pushes. - If
index_age_secondsexceeds ~3600 on a repo with recent push activity, the index is probably lagging (anext_actionsrefresh hint will fire). Your own unpushed edits are still covered via auto-overlay. - A full reindex is expensive. Avoid triggering it for individual file changes — use Tier 3 or
prism sync.
FAQ¶
Q: A teammate just pushed a fix but search_code still returns the old version. What's wrong?¶
A: Three things to check in order. (1) indexed_at / index_age_seconds on the response — if age > a few minutes, the Tier 3 webhook may have failed or queued. Check the Console dashboard for index status. (2) The push targeted a non-default branch — Tier 3 by default only indexes the default branch; for long-lived feature branches you need a registered overlay. (3) The webhook was never installed (rare — reconnecting the repo in the Console re-installs it).
Q: Why are my searches returning the same file three times with different start_line?¶
A: That's working as designed — code_chunks rows are AST-aware fragments of a file (one per function/class/method). Three hits for the same file means three different symbols matched. get_file_outline will show you the symbol structure of the file. To dedupe at the file level, use get_module_map instead.
Q: How big is a chunk?¶
A: Typically 10–80 lines for source code. The semantic chunker emits one chunk per top-level definition; large definitions are split with max_chunk_size (default ~500 chars after AST awareness). Markdown chunks split at ## headings. There is no fixed token budget — code that fits in one AST node stays in one chunk.
Q: Does Prism reindex my whole repo on every push?¶
A: No. Tier 3 runs incremental ingest — only the files in the push are re-chunked, re-embedded, and re-stored. The repo map (PageRank + module summaries) is rebuilt only when the push includes added or deleted files. Full reindex happens only when you click "Re-index" in the Console.
Q: What happens to chunks for a file I deleted?¶
A: Tier 3's _ingest_diff deletes the chunks for removed files when the webhook arrives. On a branch with a registered overlay, the deleted path lands in branch_overlays.deleted_files so read tools subtract it from default-branch results.
Q: I'm getting "description": null on freshly indexed chunks. Did the pipeline fail?¶
A: Not necessarily. Descriptions are best-effort — if Vertex or Anthropic hit a rate limit during ingest, the chunk is still fully searchable via vector + BM25 + exact legs, just without the description leg. Run the description backfill (POST /api/v1/repos/{repo_id}/backfill-descriptions) to fill the gaps. The pipeline only marks itself failed on hard errors (clone failure, DB outage), not on missing descriptions.
Q: Why does Tier 2 exist if Tier 3 covers pushes?¶
A: Latency. Tier 2 makes the index reflect your most recent local commit before you push, which is useful when you commit often or when your team queries the index frequently. It's optional — most users rely on Tier 3 plus the CLI's auto-overlay for unpushed local edits.
Q: How do I know which retrieval leg matched my query?¶
A: Every search_code response includes a provenance object listing per-leg hit counts (vector / BM25 / description / exact) and a confidence block reporting how many legs agreed. If only the exact leg matched, your query was identifier-like and didn't have semantic neighbours; if all four matched, the top hits are almost certainly right.
Q: Are my unpushed local edits searchable?¶
A: Yes, through the CLI's auto-overlay — prism sweeps git status and attaches working-tree dirty files to every read call. Today find_references re-parses overlay content in the response; search / def / body / outline / module-map / prepare-edit acknowledge the overlay but don't yet fold the content into the response (overlay_consumed: false signals this). See Branches & Overlays for the per-tool matrix.
Related¶
- Branches & Overlays — what
indexed_atmeans, when to register an overlay, how the CLI keeps reads fresh on a long-lived branch - CLI Workflow — how agents query the index this pipeline produces (
prism search,prism def,prism module-map,prism prepare-edit) - Glossary — canonical definitions for AST chunk, BM25, description embedding, four-way RRF, PageRank, Tier 1/2/3
- Console Admin — connecting a repo (which installs the Tier 3 webhook) and triggering full reindexes
- Module docs: Prism Architecture, Prism Operations — operator-level detail on partitions, HNSW tuning, and Cloud Run scaling